
Overview
 |
 |
 |
| Robert K. Nelson | Andrew J. Torget | Scott Nesbit |
In this edited interview conducted on December 8, 2011 with members of the Southern Spaces editorial staff, digital historians Robert K. Nelson, Andrew J. Torget, and Scott Nesbit discuss their training, experience, past and current projects, and the broader field of digital humanities. The interview participants reflect on potential tools for historians, the role of collaboration, and the public focus of digital scholarship.
Careers and Possibilities
How did you get your start in the digital humanities?
Robert K. Nelson: In 1997, at the end of my first year of graduate school, I needed a summer job. Ken Price taught in my graduate program in American Studies at the College of William and Mary and was the co-editor of the Walt Whitman Archive. I was interested in Whitman and nineteenth-century American literature, so I walked into his office one day and asked if he had any job openings for the summer. Ken hired me as an editorial assistant. I found that I had an aptitude for programming which I hadn’t known about. I think my continued participation in the digital humanities relates to these early experiences. I found and continue to find digital history and digital humanities to be good ways to go about studying the things that I am interested in: Whitman, Richmond, nationalism, and nineteenth-century American culture and history. It’s also a way to pay the bills, which was a significant motivation for me to walk into Ken’s office in the first place. I have been working in the digital humanities and on digital projects for about fifteen years. Despite how terrible the academic job market is, I have been able to get several jobs in the digital humanities; I've been at the Digital Scholarship Lab (DSL) at the University of Richmond since 2008.
Does digital scholarship allow you to do things that you couldn't in a traditional archive?
 |
| Robert K. Nelson, Screenshot from Mining the Dispatch, Digital Scholarship Lab, University of Richmond, 2011. |
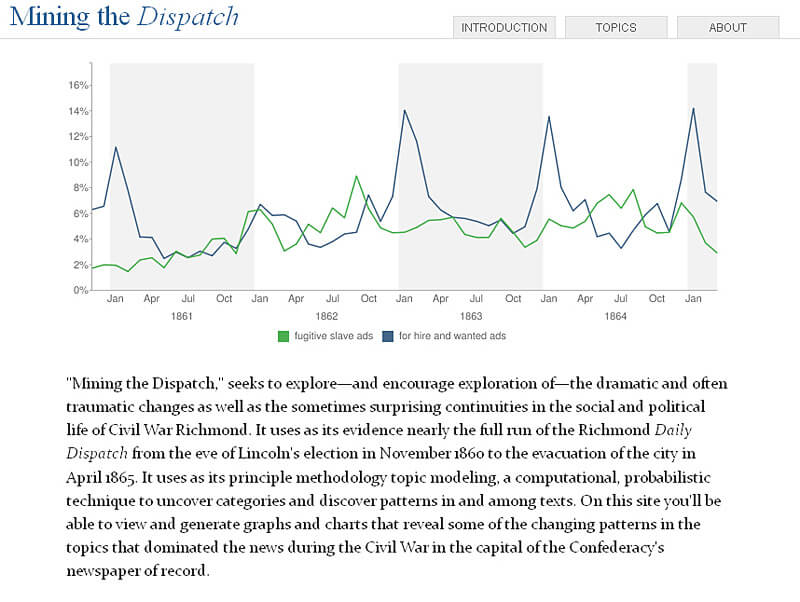
Robert K. Nelson: There are two answers to that question, and they go in opposite directions. One has only become clear to me in the last couple of years. Digital humanities allows us to think about and engage with large bodies of evidence that defy conventional methods. I am doing a lot of text mining and topic modeling, so I am dealing with bodies of texts that are simply too large for anyone to read, let alone someone as lazy as me. I am working on a couple of corpora that are massive and cover a five year period. The Mining the Dispatch project focuses on the Confederate newspaper the Richmond Daily Dispatch. We are uncovering patterns in the whole of this archive, which are really exciting and interesting, patterns that I don’t think conventional methods would allow us to see and probe in such detail.
The second thing that I think digital humanities allows and encourages more than the conventional humanities is an outward, public focus. Some people are suggesting that digital history and public history are somehow synonymous, which I do not think is the case. But a lot of the work in the digital humanities is intended for civic engagement beyond the academy. A lot of the work here at the Digital Scholarship Lab fits that category. For example, the primary audience for our Redlining Richmond project, which maps the survey data for Richmond neighborhoods amassed by the Home Owners' Loan Corporation in 1937, is our fellow citizens in the city. Our hope is that in some modest way the project will contribute to important conversations about class inequalities and race in the city. I find it exciting and rewarding to reach audiences beyond the dozen or so people who work in my micro-sub-field.
Scott Nesbit: The way that I look at it is that people who are interested in doing digital scholarship have two grindstones. One involves interfacing with a machine in ways that are sometimes difficult and tedious, much like archival work. Sometimes we are wrestling with code and how to think about it. We are coding the texts that we use while doing the same kind of archival work that everyone else is doing. We are coming up with interpretations that are in direct conversations with the work of other historians.
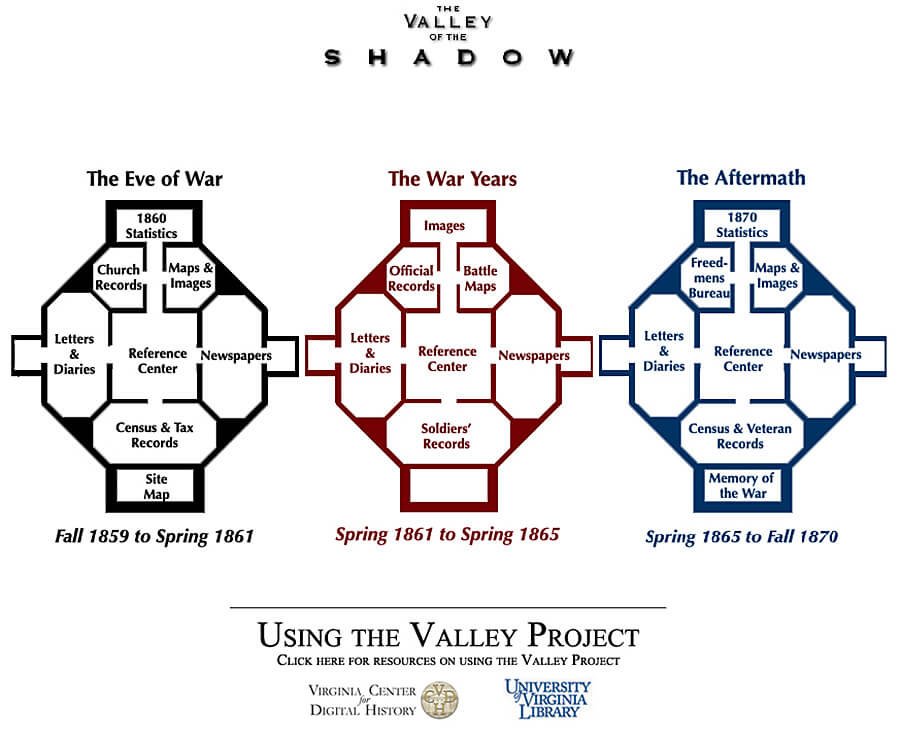
Andrew J. Torget: Your original question about how we got into the digital humanities is, from my experience, tied into why the digital and the traditional are interlaced. I got into this not because I had a grand vision that digital humanities would someday be the most important thing in my career. It was the problem of poverty. I went to graduate school based entirely on the idea that I wanted to study the South, which is why I ended up at the University of Virginia in the fall of 2001, which happened to have some of the first and most robust digital humanities centers with the Institute for Advanced Technology in the Humanities (IATH) and the Virginia Center for Digital History. It just happened that my advisor was doing digital humanities work. He had a ten-dollar-an-hour summer job available to help process documents into XML. I took the job and didn't think much about the implications of the digital medium at first. But after seeing some of the different things that might be possible with the archive that we were building—in this case, The Valley of the Shadow—I was intrigued. But I didn’t really know then how it could be different than what I could do in an analog environment.
 |
| Edward L. Ayers, Screenshot from The Valley of the Shadow: Two Communities in the American Civil War, University of Virginia, 1993. |
The turning point in engaging the digital humanities as something I wanted to build into my historical toolbox was when my advisor Ed Ayers came back from a 2005 trip to Dallas. He had a conversation with a foundation there called Summerlee which funded two different things: animal rights and Texas history projects. Fortunately, you don’t have to do both simultaneously to get a grant. They approached him because of the Valley of the Shadow project and some of his other digital work they thought was fascinating. Ed told them what we were working on, and they said, “Well, it’s got to be about Texas.” He pointed them toward me because my dissertation was on the Texas borderlands. I approached them with an idea for a project that became the Texas Slavery Project because I wanted to see what I could do with visualization and mapping. I wanted to experiment with what I could do with a particular data set. Maybe that wasn’t the most profound piece of digital scholarship, but I became convinced that there were ways that I could look at my information using digital tools that I couldn’t in an analog environment—in this case, mapping spatial relationships and textual relationships and text mining. I stuck with it because it allows me to better do what I want to do as a historian, which is answer questions. In dealing with millions of words in historical newspapers, I can build tools that allow me to see patterns in the language. I still do all the things that my friends from grad school who did not engage digital history do, such as close readings of traditional sources and deep archival work. But digital methods give me more tools to do what we’re all trying to accomplish, which is to answer questions. It allows me to better deal with the deep complexity of the past and the deep complexity that comes from having to deal with large quantities of information.
The academy has been dinged for scholars having such sub-specializations in their fields. Someone can write an entire book about one small county in one decade. But instead of being a reflection of academics being narrow, it’s really a reflection of the fact that we have so much more access to information and historical scholarship on particular topics that you really have to become a sub-specialist just to wrap your arms around the information and scholarship that’s gone before you. The way that our field has dealt with that challenge over the past few decades is by sub-sub-sub-specializations. The digital revolution, however, offers us the opportunity and tools to pull back from such hyper-specialization because the machinery is now capable of moving so many different parts around simultaneously, allowing historians to look at larger patterns and connections over a broader picture. The traditional goals of history haven’t changed, and some of the same tools stay in its toolbox, but these digital methods add a new dimension to what our goals have always been.
Digital History and the "Virginia Diaspora"
What is the place of digital scholarship at places such as the University of Richmond and the University of North Texas, and in the broader academy?
Robert K. Nelson: Ed Ayers is the president of the University of Richmond, and is a major southern historian and an early and celebrated practitioner of digital history. The Digital Scholarship Lab (DSL) is almost unique as a digital humanities research center at a small liberal arts college (we have some professional schools here, but we’ve got fewer than five thousand students). I can’t think of another center like us at a similarly sized institution. We are unique in part because our president is engaged in the field of digital humanities and has made it a priority at Richmond.
I think our center is sized correctly for us. A university such as George Mason might have a staff of fifty or more, a place like Nebraska will have a comparatively large digital humanities center. We’re a staff of three. I think that encourages us to carve out a niche. We’ve done some projects on Richmond and the state of Virginia. We’ve done some projects on the South. And we’ve done some projects on the United States. Most of these projects have focused on the Civil War-era. We have some large ambitions, but until we’ve amassed sufficient grants we’ve had to carve out a niche, which is nineteenth-century American and southern history.
Andrew J. Torget: I’m part of what I call the “Virginia diaspora,” the folks that have come out of the University of Virginia. In 2007, I moved over to the University of Richmond for all the reasons that Rob was just describing. In 2009, I got hired at the University of North Texas, in part because UNT didn’t have what the University of Virginia has, and what the University of Richmond has now—which is a presence in digital scholarship. UNT has done what a lot of universities have done: build up their digital archiving and library systems. But they hadn’t experimented with doing new types of scholarship with that content. I was hired in the history department, but part of my job duties are to build a lab to get the ball rolling. UNT is doing what I think a lot of universities are starting to do, realizing that if they don’t start moving soon, they’ll always be playing catch-up. UNT is putting money into architecture and infrastructure, as people like Martin Halbert—the new library dean at UNT—help lead the university toward the digital future. The lab builds on the connections between folks like Rob and Scott and the rest of the DSL, as well as the rest of Virginia, because so much work has come out of UVA and George Mason.
I’ve also noticed that there’s been a real movement across the country as departments say digital humanities are part of what they’re looking for. I’ve been struck by how English departments seem to be ahead of history in terms of producing graduate students and new PhDs who are actively engaging with digital scholarship. They’re usually involved with texts, which makes sense, as opposed to visualization and spatial analysis.
Scott Nesbit: As for the future of digital humanities, I don’t foresee a separate discipline but a trajectory in which those who study literature, history, or other humanities—and use computers to do so—are folded into existing disciplines.
Andrew J. Torget: I agree with Scott. I think that there will always be a need for deep context in a particular field, like historical background so that, for instance, you can make sense of nineteenth-century language patterns. What I find interesting is that digital projects by necessity require collaboration. It’s a necessity to have somebody with a deep specialization in history working with someone who has a deep specialization in natural language processing and computer science to be able to do effective and cutting-edge work in text mining or language analysis and produce reliable and useful insights. The disciplines won’t go away, and departments probably won’t either, but I see a movement towards collaborative teams built around projects and problems that will last for as long as the project or problem does. You may have a home department, but you will also have collaborative teams that form and dissolve over time depending on what you’re working on.
Collaboration
Can digital scholarship provide a model for collaborative work in the humanities?
Robert K. Nelson: Collaboration tends to be the norm in digital humanities. In most cases, humanists don’t have the technical skills to tackle digital projects by themselves. Feeling unqualified or intimidated can become a reason for some scholars not to avail themselves of digital methodologies. While I wouldn't want to understate some of the technical challenges to practicing digital history, many historians can do this type of work, and for some projects large collaborative teams are not necessary. My Mining the Dispatch project is an example. I benefited from ideas from many people, but it is in some respects a one-person show. I did the programming, wrote the interpretation, and did the design. Having said that, Mining the Dispatch is an exception to the work we do at the DSL. I can’t actually think of another project that isn’t deeply collaborative, that involves not only people from the Digital Scholarship Lab, but historians from other universities, or other members of our university who have technical skills.
Andrew J. Torget: I would not disagree with you, Rob. You are unique in having deep skills in programming, in addition to your knowledge of nineteenth-century America. I’m also in agreement with people like Steve Ramsay at the University of Nebraska who say that you have to program and you have to code to understand all of this. I think that there’s a need to be digitally literate. It’s easy to hand an idea to a programmer and treat it like a black box. You don’t have any sense of what output is valid, whether it’s text mining and you’re working with MALLET, or you’re doing some sort of geospatial analysis in GIS and you don’t know what the Esri tools are doing. I think that there’s a danger with graduate students now, who can engage this material but don’t have the opportunity to build up literacy.
I don’t intend to try to stay on top of the literature of natural language processing because I don’t have the time to do it effectively. While I know enough about the text mining work that I’m doing right now in collaboration with a colleague in computer science, I can’t do what she does and I don’t want to do what she does. I need to know enough, however, to have an intelligent conversation with her so that we can make the right choices. There has to be a digital literacy of a certain level.
Robert K. Nelson: I think that’s absolutely right, and I may have overstated the lack of collaboration on Mining the Dispatch because the project could not have been done without the MALLET topic modeling software produced by Andrew McCallum and others at the University of Massachusetts Amherst. I’m a pretty competent programmer, but I’m not a statistician, and I’ve talked to statisticians who don’t understand fully the topic modeling algorithm I've been using, latent Dirichlet allocation. I have no hope of understanding it in anything but conceptual terms, but I haven't found that a barrier to using topic modeling to explore the Dispatch and the New York Times. MALLET generates a collection of materials and visualizations that demand and lead to what I think are interesting interpretations. For instance, topic models of the Richmond Daily Dispatch and the New York Times during the Civil War suggest that, unsurprisingly, northerners and southerners used the same rhetoric of nationalism and patriotism. But graphs of that rhetoric in the papers suggest an interesting insight: they may have used the same rhetoric, but the editor of the Dispatch used it to draw men into the army and the editor of the decidedly Republican Times to draw them to the polls.
Scott Nesbit: This kind of asynchronous collaboration is actually quite familiar because historians are accustomed to building on both the literature and the apparatus for scholarship that has come before them. We all use documentary collections that were published around the turn of the last century. To take Rob’s text mining project as an example, it’s a kind of asynchronous collaboration with the scholars who created the MALLET tools at the UMass Amherst, as well as scholars who edited and put together the XML text for the Daily Dispatch at Tufts University and here at the University of Richmond before either of us arrived. The collaborative opportunities afforded by digital humanities are quite familiar ones.
What's your relationship with other digital centers, projects, and organizations?
Andrew J. Torget: I think there’s a real danger identifying ourselves as separate, because then it’s easy for any given department to say, “Well, that’s something different, that’s the whole digital humanities thing—who cares!” What I think we need more of are projects that build insights based on digital techniques, and use that to answer a traditional question, incorporate it into traditional methods, and publish it in a respected publication. We need more in the Journal of Southern History. The American Historical Review had several digital articles, but they were ignored for the most part simply because they were all digital. Because their medium was completely digital, many people chose to dismiss what they had to say. What we need is to interweave all of this so that the digital humanities isn’t seen as its own discipline, but as part of disciplines like history.
Robert K. Nelson: I think Andrew said that very well. This is a small community, and I feel like we have good relationships with several centers. At Richmond, we don’t have any particularly deep collaborative relationships with other digital humanities centers, though we do benefit from their work, and I hope that we’ve helped their work in turn. The largest of all digital humanities centers, the Roy Rosenzweig Center for History and New Media, seems to have been focused largely in the past few years on general purpose, content-agnostic software packages like Zotero and Omeka. We’ve used Omeka once or twice on different things, and that’s a great piece of software. It’s very easy to use and very useful for archivists, librarians, museum professionals, and historians who want to build digital archives. It’s thoughtful and fills a need in the scholarly community, and we certainly have availed ourselves of it.
Digital Scholarship for Many Souths
How do these new tools, methods, and perspectives change how people think about and do scholarship about the US South?
Scott Nesbit: One of the most interesting questions about the South is its extent. Matt Lassiter has been talking about the end of the South with suburbanization after World War II, and scholars in other periods are deeply interested in the boundaries of the South in order to question how it is really a coherent concept. To me, these questions are fundamentally geographic and they are especially suited for nuanced digital interpretation. For example, one can imagine a map of many regions of the South that would have types of demographic data that scholars like Lassiter have come up with alongside other imaginings that are much more humanistic. To think of those layered on the landscape is potentially a powerful development.
 |
| Digital Scholarship Lab, Screenshot of Voting America: United States Politics, 1840–2008, "Dot-Density Map of Presidential Voting, 1920," University of Richmond, 2011. |
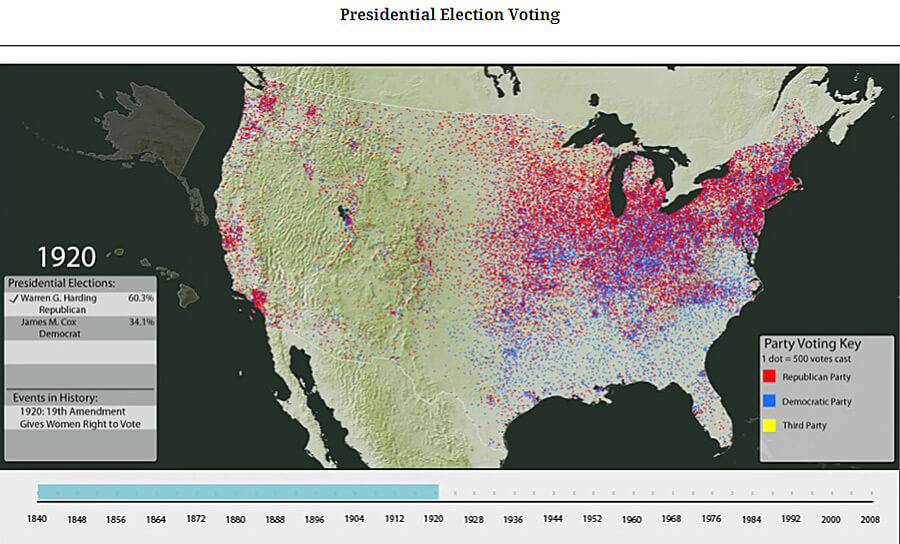
Andrew J. Torget: I work on the western edge of the US South, and the question at the essence of this is a spatial one. There’s been a lot of discussion in historical circles, digital and otherwise, about the spatial turn, especially in western historiography. I think that the digital environment allows a much more nuanced vision of the spatial dimensions of the South, as Scott said. We did the Voting America project that looked at voting patterns over time. One of the things that I found striking about the maps was how distinct the South was visually in historical voting patterns. A dot density map of the South after the Civil War shows the effects of Jim Crow disenfranchisement, especially as you move towards the 1920s and the civil rights movement. That is something at the heart of southern history—what makes this area so different, and what does it share with the rest of the United States? The spatial aspect of digital humanities is uniquely capable of dealing with networks—networks of people and ideas in and out of the South.
Projects
What are the specific projects that you are all working on? How were these projects conceived, and how did they become digital?
 |
| Andrew J. Torget, Screenshot from The Texas Slavery Project, 2008. |
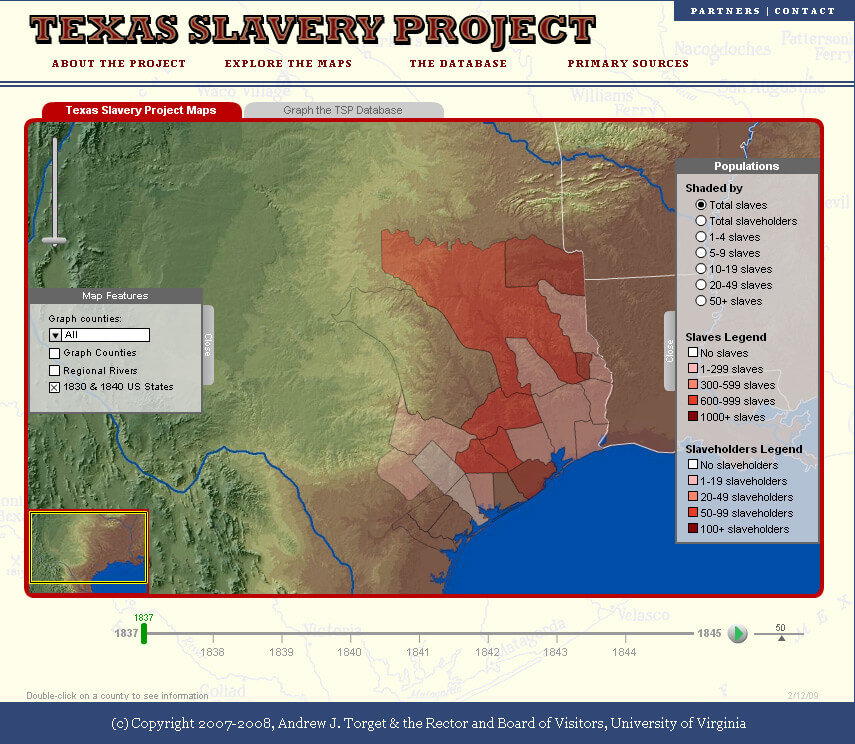
Andrew J. Torget: The Texas Slavery Project came out of my dissertation. I had a question that I was trying to answer, and I happened to find a set of data that I didn’t have a good way of dealing with: tax records from Texas during the 1840s and 1830s. Texas was an independent republic for ten years, and the way I describe it is everything the Confederacy wanted to become but never had a chance to be—an independent republic of slaveholders who grew cotton and lived outside the United States. This proved interesting for my project because they kept records every year of all the taxable property that people had, including enslaved people. I created a database of it. It’s not dissimilar from most of the massive datasets that we have, in terms of voting records and population records. I found them in tables that were really dissatisfying. I couldn’t see relationships between places, and I certainly couldn’t understand change over time. Building a database was key to the Texas Slavery Project, then creating a mapping interface that enables viewing the movement of people across time and space. It was incredibly useful for conceiving the changes in this territory over a ten year period. It told us a lot about how slavery and the South was expanding prior to the Civil War. It all came out of my central research question. Most of my projects start from a question and then lead to some digital tools that help analyze and answer an aspect of that question.
 |
| Digital Scholarship Lab, Screenshot from Redlining Richmond, 2011. |
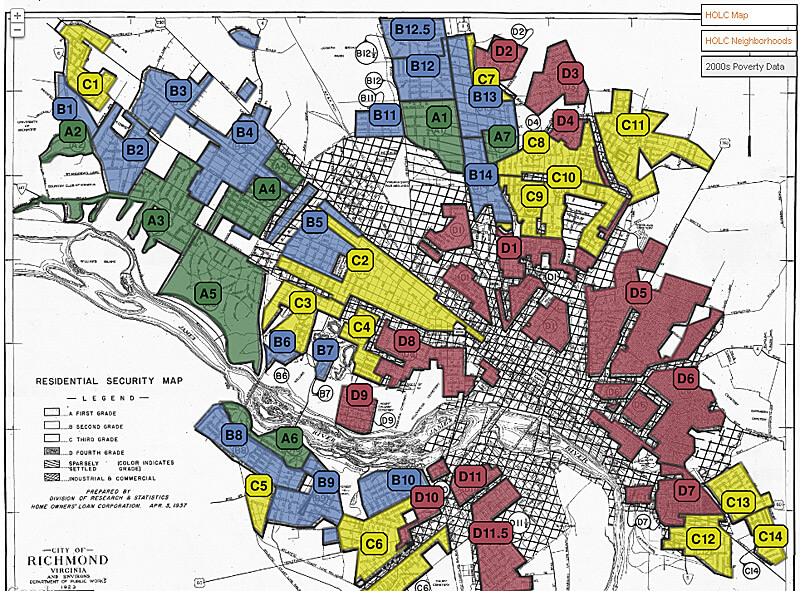
Robert K. Nelson: I’ll talk about a couple of things. One is Redlining Richmond, which is a pretty modest project that we did that’s on a wonderful map—wonderful in the sense of being really interesting, though certainly terrible for its racialist and racist motivations. In the midst of the Depression, Roosevelt, working with the Home Owners' Loan Corporation (HOLC), got the federal government involved in refinancing. I think about a million homes were refinanced during the Depression.
Redlining Richmond came out of a conversation that I had with a friend and colleague here at the University of Richmond, John Moeser, who is a student and scholar of twentieth-century Richmond. He had photocopies of these surveys that were done in the 1930s, and the map in his office, and I thought, “This is a perfect digital project.” The HOLC filled out a survey, they had a discrete number of questions that they asked across different neighborhoods, they made a map of it—this was exactly what we’d do with structured data, and they’d already done it, so it struck me as a perfect project to put into a digital form so that you could make these interesting and important surveys more accessible. But then you could also map pieces of data besides the grade they assigned each neighborhood—what they did at the end was give each neighborhood an A, B, C, or D which was an evaluation of the safety of mortgages in those communities; for each city the HOLC produced a residential security map that showed these grades. What I wanted to do was to let somebody map discrete, particular pieces of that information from the survey. So if somebody was interested in income, you could map the HOLC's survey data and see a visualization of income distribution in 1930s Richmond.
The larger point of this is that this is one of our more civic engagement-oriented projects. We took some inspiration from Karen Halttunen, the former president of the American Studies Association, who called upon scholars to engage in what she called “place-making practices” to not ironically step back and assume this scholarly distance from the ways that places get culturally and socially constructed but to have our scholarship actually and intentionally engage in that process, and in our case, make people aware of past injustices.1Karen Halttunen, “Groundwork: American Studies in Place—Presidential Address to the American Studies Association, November 4, 2005,” American Quarterly, 58.1 (March 2006), 1-15. This is very much a civic engagement-oriented project that we hoped would spur people in the city to talk about this history of race, to talk about the history of economic and social inequality and how that’s spatialized on the landscape. It’s had some of that effect. It’s been talked about in neighborhood blogs around the city. John Moeser is a member of our city’s anti-poverty commission, and he’s used these when talking to his fellow members of that commission to educate them about the long history and some of the structures that have encouraged persistent poverty among some communities and some neighborhoods over the course of, in this case, eight decades.
Scott Nesbit: Visualizing Emancipation took its origins in a way similar to what Andrew described with the Texas Slavery Project. We had questions about how emancipation was different in different places. There’s been a great deal of work and documentary reflections about emancipation produced over the last twenty years, but increasingly powerful tools such as GIS mapping can help us grasp that huge body of evidence in sophisticated ways.
Robert K. Nelson: I’ll talk briefly about Mining the Dispatch. We had here a recently-digitized full run of the Richmond Daily Dispatch, one of the most important papers of the Confederacy, from Lincoln’s election in the fall of 1860 through a little past the end of the war. It’s a substantial archive, with over 100,000 articles and advertisements, amounting to just short of 24 million words—not unlike a lot of large digital collections.
 |
| Robert K. Nelson, Screenshot from Mining the Dispatch, Digital Scholarship Lab, University of Richmond, 2011. |
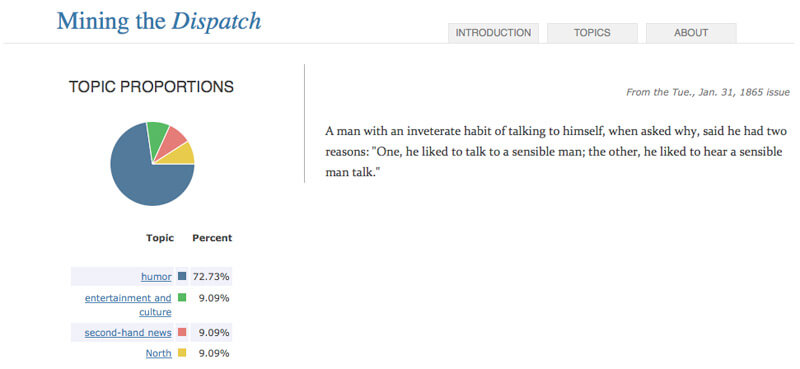
I’d read a 2006 article by Sharon Block in Common-Place on topic modeling, a text mining technique which uncovers topics and word distributions for massive amounts of text.2Sharon Block, "Doing More with Digitization: An Introduction to Topic Modeling of Early American Sources," Comon-Place 6 (January 2006), http://www.common-place.org/vol-06/no-02/tales/. These usually have some kind of semantic, interpretive substance—you can look at the words and go, “Oh, I know exactly what this is. This is a topic on fugitive slave ads.” I was intrigued. With the release of the MALLET toolkit out of UMass Amherst, topic modeling became something that you didn’t need a computer scientist friend/colleague/partner to do. I used MALLET and threw a couple of large texts into it, the main one being the Richmond Dispatch, and I was really shocked by how interesting the results were and how subtle some of the topics were that it would pick up. If you go to Mining the Dispatch, there’s a topic on humor. It seemed impossible to me that a statistical program that knows nothing about the meaning of words and is just looking for collocations—words that often appear together in individual articles—would pick up something as subtle as humor. I looked at the articles most associated with one topic, and they were these little jokes that I didn’t even know were in the paper.
This technique uncovered the relationship between Confederate nationalism and patriotism, and helped me to distinguish between the two. Patriotic and nationalistic pieces would appear in the paper at certain moments, but used very different rhetoric and did different though related cultural and political work. Patriotic articles featured poems and rhetoric that was very positive, often about objects of reverence—God, country, home—or about martial virtues—glory, nobility, duty, honor. The nationalism articles were completely different in tone. They were vicious unflinching attacks on northerners and northern society, condemning them in the most vitriolic terms. It occurred to me that these two rhetorics were doing different things to alleviate guilt or hesitation for men who might join the army. The patriotic tone made it easier to risk dying, whereas the nationalistic diatribes and philippics dehumanized northerners and made it palatable to kill them. This opened up interpretive opportunities to understand Confederate nationalism. I’m expanding the work to compare it to northern nationalism by using the same kinds of models to study the New York Times.
Audiences
Who are the audiences for these digital projects, and what do you want them to learn when they go to your sites?
Andrew J. Torget: That’s an interesting question because history, more than most disciplines, often has a public as well as an academic audience. There’s a popular appeal that maybe physics doesn’t always enjoy. With the digital there are more opportunities to engage. Whether it’s Texas Slavery Project or Voting America, or the one I’m working on now with Stanford called Mapping Texts, we want to engage academics, but also a general audience who is interested in the Civil War, or migration, or the West, or South. The digital allows for conversations outside the traditional research setting of historians. With my Texas Slavery Project, I get emails from people who are tracking down their relatives or from people who have letters in their attic dealing with slavery in the 1840s that I never would have found.
While digital humanists often try to engage the public and other digital humanists, most of us make little effort to reach academics who are not themselves working digitally. Other digital humanists often look at our stuff in a scholarly sense, but we don’t tend to engage the broader academic audience. What Rob articulated about the Richmond Dispatch is fantastic, and he’s actually done more than most to write the scholarly discourse, but we don’t typically publish in formats that will engage non-digital humanists. That means non-digital humanists are rarely challenged to think, “Maybe I should have some sense of how this digital methodology has helped him answer this big question that I’m also trying to answer." The irony is that we tend to not engage our traditional academic audience as much as we probably should, even while we actively try to engage the public much more than our academic colleagues do.
 |
| Digital Scholarship Lab, Screenshot from The History Engine: Tools for Collaborative Education & Research, University of Richmond, 2009. |
Robert K. Nelson: I agree with Andrew. For Mining the Dispatch, its main audience has been other digital humanists, and they are interested in it as a methodological experiment. But I want it to engage historians of the Civil War and of nineteenth-century nationalism. We design other projects to have broader public appeals, and often—Redlining Richmond being the clearest example—there’s a local audience. These are civic engagement, digital history projects that are aimed at the place we live.
We’ve all worked together at different moments on the History Engine, a pedagogically-oriented site where the contributions come from research and historical vignettes that students write. For the DSL, that’s by far the project that gets the most traffic, sometimes ten thousand visits a month. For the History Engine, students carry out assignments to learn the process of doing historical research and writing. We’re very pleased that the product is of interest to a much larger public.
Funding
Given that these projects have multiple levels of content and appeal, how did you go about getting funding, and what kind of support structures exist for scholars at the beginning stages of digital projects?
Andrew J. Torget: When I started the Texas Slavery Project, I was a graduate student. The University of Virginia has resources, including start-up funds for digital and non-digital projects. I know here at UNT, there are research initiation grants that are in-house, small-time funding sources. As I mentioned earlier, my first foray was to approach the Summerlee Foundation. I have found over the years with different projects that private foundations are a great resource and almost every university has an office whose purpose is to help researchers find support. There are many small foundations whose first impulse isn’t to say, “We want to fund digital projects,” but they may be interested in your research from a cultural, sociological, economic perspective. They might give you a grant for $2,000 or $20,000 to build a prototype that would enable you to go for bigger funding from the NEH. All three of us have been beneficiaries of the Office of Digital Humanities at the NEH; their digital start-up grants have helped us build interesting and exciting projects. You’ve got to be entrepreneurial, imaginative, and persistent. There are also online fundraising tools like Kickstarter where you post an idea and raise funds online.
Scott Nesbit: I would like to reiterate what Andrew said about looking for sources of funding that are not specifically earmarked for digital humanities, especially for people who are in graduate school or starting out. A lot of the dissertation fellowships would be perfect for this, and there are small grants at a number of institutions that will allow you to pursue a digital humanities project. Larger institutions often have support for graduate students who have small-scale projects that they’d like to pursue. If people at smaller liberal arts colleges have projects that are similar to larger, ongoing projects, digital humanities centers often have ways to partner. DHCommons tries to pair up people who have good ideas for projects but don’t have the support of a center, with digital humanities centers. We’re still in the early years of figuring out how to fund projects, but those are two very good routes.
Andrew J. Torget: One more thing to add is to think iteratively. Most scholars who come to digital humanities at the outset walk in thinking, “I need one of those $300,000 grants from the NEH.” But people want to fund winners. If somebody puts money into your project—even if it’s your own university for $500—that helps get the ball rolling toward convincing others to put money in. Before you approach a big organization like the NEH, it behooves you to beat the bushes locally and build something with internal funds to not just show a prototype that actually works, but to show that your institution and the area around you has put support and interest into the project.
Changes and Challenges
How has digital humanities changed over the years that you've been involved?
Scott Nesbit: The most striking thing to me is the way that it has become a topic of conversation in the larger disciplines, which was not the case when I started working in the digital humanities six or seven years ago. Increasingly you are seeing job advertisements and panels at scholarly meetings (such as this year’s American Historical Association convention) focusing specifically on digital methods and digital scholarship.
Andrew J. Torget: I would agree in the sense that there is a wider appreciation that somehow, some way, this is going to be something. But we are still wringing our hands about what that is. With digital humanities groups, you see these incredibly long, detailed definitions of what the “digital humanities” actually is, and their definitions usually attempt to encompass just about everything. For me, digital humanities was, and always has been, engaging our questions using digital tools and techniques, and dealing with the reality of information being available in digital forms. That is kind of it. Universities are starting to see this as being actually relevant. Regarding the scholarship, my colleagues across the discipline don't know what to make of this work yet, because we have not given them enough good examples that actually produce insights and advances in knowledge that couldn’t have been done any other way. I think we digital humanists are still talking mostly to each other, although that is changing.
Robert K. Nelson: I agree with Andrew. In terms of digital scholarship, we need to amplify the “scholarship” aspect of the work. That seems to be the primary challenge at this moment. A lot of the early projects were oriented toward amassing large archives of materials, like the Valley of the Shadow project, the Walt Whitman Archive, and the Rosetti Archive. These are all great projects, but they were, for the most part, archives, and they saved interpretation for print scholarship. In some ways, we are still in that mode. Omeka, for example, is not an interpretation-oriented tool—it is meant to build more archives. But at the same time there is a need for the digital humanists to use these methods and techniques to do scholarship, to present and develop arguments, to arrive at interpretations and perspectives that offer us new knowledge about the past and about human culture.
Andrew J. Torget: We need to put this work in places where people will engage with it who aren’t already in agreement with me that the digital approach is a fine one to use. One of the things I loved about my digital projects, Texas Slavery Project being the best example, is that they speed up the historiographic conversation. I will give a talk, and use my Texas slavery maps to make an argument. I show the audience the evidence as I used it, and the way I used it, but the interesting part is that people will raise their hands and say “You know, I see something completely different in your maps, and I think you are wrong.” There is something wonderful and exciting that is at the essence of the iterative aspect of scholarship. But we are often speaking to the converted in terms of methodology and are not doing a good enough job of engaging scholars who have no idea what topic modeling is, or have any concern about it whatsoever.
Robert K. Nelson: It is a hard challenge for us as historians who are using digital tools, techniques, and methods, using algorithmic and computational approaches to studying the past. These have to reveal something new, interesting, and important. It’s starting to happen. I think of Will Thomas’s recent book The Iron Way: Railroads, the Civil War, and the Making of Modern America, which relied on digital techniques.3TWilliam G. Thomas, The Iron Way: Railroads, the Civil War, and the Making of Modern America (New Haven, CT: Yale University Press, 2011).
Andrew J. Torget: Don’t you feel like part of the problem is how we explain what these topic models are, for example, that you use with the Dispatch and I use with Mapping Texts? The tremendously deep complexity of the algorithms and mathematics in these statistical models means that—in the case of topic modeling—I am not always one hundred percent certain what those results are modeling. I know that the patterns they expose often appear highly relevant, but how can we better understand what the math and the algorithm is really kicking out? We have to wrestle, I think, with the question of whether the methodology will hold up fully to the scrutiny of a particular point.
Robert K. Nelson: I think in this particular instance, Andrew, the challenge is to toggle between distant and close readings; not to rely solely on topic modeling and visualizations, these massive aggregations of texts, as your only source of evidence, but to use that in conjunction with more traditional close readings. That will make it easier to stomach for most people, and make it easier to understand for most scholars. It also makes for better writing, because these distant readings can be really exciting but they often kind of miss the engaging historical storytelling or that illuminating example that can only come from reading lots and lots of texts.
Andrew J. Torget: I agree. That is why I always emphasize not separating traditional methods from the digital. These things come together because any one kind of source is not going to give the whole story. We are not always very good at articulating the insights that sometimes seem self-evident in our digital projects. We need to explain effectively why we think these projects offer insights in ways that will convince somebody who isn’t interested in being convinced.
Robert K. Nelson: One thing that the best digital humanities projects continue to do is to engage wider attention, to engage in public history and civic engagement, to reach K–12 students, and international audiences. 
Recommended Resources
Bodenhamer, David, John Corrigan, and Trevor M. Harris, eds. The Spatial Humanities: GIS and the Future of Humanities Scholarship. Bloomington: Indiana University Press, 2010.
Cohen, Daniel and Roy Rosenzweig. Digital History: A Guide to Gathering, Preserving, and Presenting the Past on the Web. Philadelphia: University of Pennsylvania Press, 2005.
Fitzpatrick, Kathleen. Planned Obsolescence: Publishing, Technology, and the Future of the Academy. New York: New York University Press, 2011.
Rosenzweig, Roy. Clio Wired: The Future of the Past in the Digital Age. New York: Columbia University Press, 2011.
Schreibman, Susan, Raymond George Siemens, and John M. Unsworth, eds. A Companion to Digital Humanities. Oxford: Blackwell, 2004.
Weller, Martin. The Digital Scholar: How Technology is Transforming Scholarly Practice. London: Bloomsbury, 2011.
Links
Center for Digital Research in the Humanities, University of Nebraska-Lincoln
http://cdrh.unl.edu/.
Digital Scholarship Commons, Emory University
http://web.library.emory.edu/disc.
Digital Scholarship Lab, University of Richmond
http://dsl.richmond.edu/.
IATH, University of Virginia
http://www.iath.virginia.edu/.
Roy Rosenzweig Center for History and New Media, George Mason University
http://chnm.gmu.edu/.
Projects
Hidden Patterns of the Civil War
http://dsl.richmond.edu/civilwar/.
History Engine: Tools for Collaborative Education and Research
http://historyengine.richmond.edu/.
MALLET: MAchine Learning LanguagE Toolkit
http://mallet.cs.umass.edu/.
Mapping Texts
http://mappingtexts.org/.
Mining the Dispatch
http://dsl.richmond.edu/dispatch/.
Omeka
http://omeka.org/.
Redlining Richmond
http://dsl.richmond.edu/holc/.
Rosetti Archive
http://www.rossettiarchive.org/.
Texas Slavery Project
http://www.texasslaveryproject.org/.
Valley of the Shadow: Two Communities in the American Civil War
http://valley.lib.virginia.edu/.
Voting America
http://dsl.richmond.edu/voting/.
Walt Whitman Archive
http://www.whitmanarchive.org/.
Zotero
http://www.zotero.org/.
Similar Publications

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1. | Karen Halttunen, “Groundwork: American Studies in Place—Presidential Address to the American Studies Association, November 4, 2005,” American Quarterly, 58.1 (March 2006), 1-15. |
|---|---|
| 2. | Sharon Block, "Doing More with Digitization: An Introduction to Topic Modeling of Early American Sources," Comon-Place 6 (January 2006), http://www.common-place.org/vol-06/no-02/tales/. |
| 3. | TWilliam G. Thomas, The Iron Way: Railroads, the Civil War, and the Making of Modern America (New Haven, CT: Yale University Press, 2011). |